
In der heutigen datengetriebenen Welt wird der effiziente Zugriff auf Informationen immer wichtiger. Unternehmen, Forschungseinrichtungen und Fachkräfte stehen vor der Herausforderung, riesige Mengen an Dokumenten, Berichten und unstrukturierten Daten effizient zu durchsuchen. Klassische Suchalgorithmen stossen oft an ihre Grenzen, wenn es darum geht, semantische Zusammenhänge zu verstehen und präzise Antworten auf spezifische Fragen zu liefern.
Hier setzt Retrieval-Augmented Generation (RAG) an: eine Methode, die die Leistungsfähigkeit von Sprachmodellen mit einer robusten Suchstrategie kombiniert. Während herkömmliche Suchmaschinen oft nur Schlüsselwörter abgleichen, bietet ein RAG System die Möglichkeit die Leistung von Sprachmodellen auf einen bestimmten Kontext einzugrenzen, indem es semantische Ähnlichkeiten erkennt und diese für die Generierung präziserer Antworten nutzt.
Das Ziel mit diesem Prototyp war es, ein intelligentes System zu entwickeln, das den Such- und Entscheidungsprozess beschleunigt und gleichzeitig qualitativ hochwertige Antworten liefert. In einer Welt, in der Zeit ein wertvolles Gut ist, kann ein solches System einen erheblichen Produktivitätsgewinn ermöglichen – sei es bei der Recherche, im Kundenservice oder bei der internen Dokumentation grosser Unternehmen.
Hier stelle ich einen Prototypen für ein Information-Retrieval-System vor, das mit RAG arbeitet. Das System ist mit Flask als Web-Backend aufgebaut, nutzt ChromaDB für embeddings-basierte Suchanfragen und bietet eine intuitive Web-UI, die eine einfache Interaktion ermöglicht.
Technologische Grundlage
Das System besteht aus folgenden Hauptkomponenten:
- Flask & FastAPI: Web-Frameworks für die API und das User-Interface.
- ChromaDB: Vektordatenbank für das embeddings-basierte Retrieval.
- Langchain: Framework zur Orchestrierung von Retrieval- und Generationsprozessen.
- Hugging Face Modelle: Transformer-Modelle für Embeddings und Generierung.
- PyMuPDF: Verarbeitung von PDF-Dokumenten zur Indexierung.
- Web-Frontend (HTML, CSS, JavaScript): Eine Benutzeroberfläche für Interaktionen mit dem System.
Die wichtigsten Dependencies sind in der Datei requirements.txt zu finden.
Hier einige relevante Bibliotheken:
- chromadb==0.5.3
- langchain==0.2.14
- sentence-transformers==3.1.0
- transformers==4.44.0
- Flask==3.0.3
Diese Kombination ermöglicht ein effizientes Information-Retrieval mit semantischem Verständnis.
Systemarchitektur
Das System besteht aus mehreren Modulen:
- app.py: Die zentrale Flask-Applikation, die Anfragen entgegennimmt und verarbeitet.
- routes.py: Definiert API-Endpunkte für das Hochladen, Indexieren und Abfragen von Dokumenten.
- utils.py: Enthält Helferfunktionen zur PDF-Verarbeitung und Embedding-Generierung.
- config.py: Speichert Konfigurationsvariablen für das System.
- LLM.html & upload.html: Das Web-Frontend für Suchanfragen und Dokumenten-Uploads.
- style.css: Design-Elemente für eine ansprechende Benutzeroberfläche.
Ein typischer Workflow sieht folgendermassen aus:
- Ein Dokument (z. B. PDF) wird über die Web-UI hochgeladen.
- Der Inhalt wird extrahiert und in kleinere Textblöcke zerlegt.
- Für jeden Textblock wird ein Embedding generiert und in ChromaDB gespeichert.
- Bei einer Suchanfrage wird das Query ebenfalls als Embedding berechnet.
- ChromaDB führt eine Vektor-Suche durch und gibt die relevantesten Passagen zurück.
- Ein Sprachmodell generiert eine kohärente Antwort basierend auf den Ergebnissen.
- Die Antwort wird in der Web-UI angezeigt, inklusive der relevanten Dokumentenquellen.
Code-Einblick
Hier ein kurzer Blick auf die Suchfunktion, die ChromaDB nutzt (im Code etwas anders umgesetzt):
from langchain.chains import RetrievalQA
query = request.form.get(‚inputString‘)
retriever = vector_store.as_retriever()
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type=»stuff»,
retriever=retriever,
return_source_documents=True
)
result = qa_chain({«query»: query})
Diese Methode nimmt eine Benutzeranfrage entgegen, wandelt sie in einen Embedding-Vektor um und führt eine Ähnlichkeitssuche durch. Die besten Treffer werden dann für die Generierung der finalen Antwort genutzt.
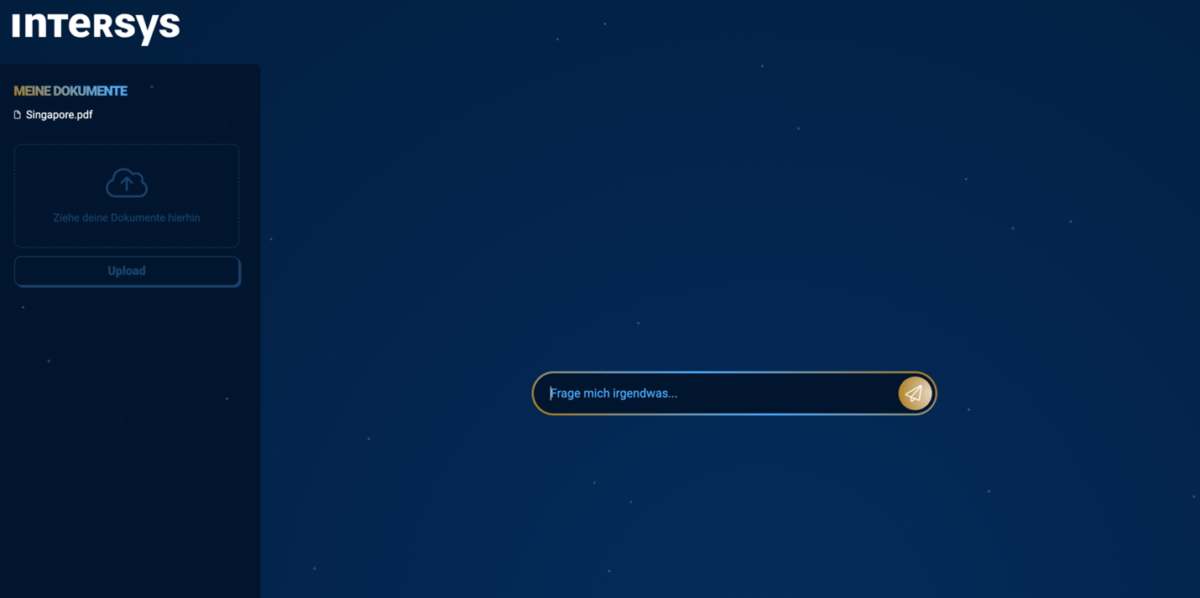
Benutzeroberfläche
Das System verfügt über eine intuitive Web-UI, die in LLM.html und upload.html definiert ist. Sie bietet folgende Funktionen:
- Eingabefeld für Suchanfragen mit direkter Antwortanzeige.
- Darstellung der gefundenen Dokumente und relevanten Abschnitte.
- Dokumenten-Upload mit einer Anzeige der bereits gespeicherten Dateien.
- Responsive Design für eine angenehme Nutzung auf verschiedenen Geräten.
Das Styling der UI wird in style.css verwaltet und sorgt für eine moderne, nutzerfreundliche Optik.
Herausforderungen und Optimierungen
Während der Entwicklung sind einige Herausforderungen aufgetreten:
- Optimierung der Embeddings: Die Wahl des richtigen Modells beeinflusst die Suchqualität erheblich. all-MiniLM-L6-v2 bietet eine gute Balance zwischen Performance und Geschwindigkeit.
- Speicherung grosser Dokumente: Durch Chunking wird verhindert, dass lange Texte die Datenbank überlasten.
- Latenzoptimierung: Durch Caching und parallele Verarbeitung konnte die Antwortzeit reduziert werden.
- UX-Optimierung: Die UI wurde so gestaltet, dass Nutzer schnell zwischen Uploads und Suchanfragen wechseln können.
Fazit und Ausblick
Dieser Prototyp zeigt, wie sich RAG in einem Information-Retrieval-System effektiv einsetzen lässt. Die Web-UI erleichtert die Nutzung und ermöglicht eine interaktive Exploration von Dokumenten.
In Zukunft sind weitere Verbesserungen geplant, wie die Integration von leistungsstärkeren LLM oder eine erweiterte Visualisierung der Suchergebnisse. Hier handelt es sich zur Zeit noch um einen recht rudimentären Prototypen.
Diese Technologie bietet vielfältige Einsatzmöglichkeiten – von einfachen Information-Retrieval-Aufgaben bis hin zu komplexeren Anwendungen. So kann sie beispielsweise als zentrale Wissensbasis dienen, um Mitarbeitende schnellen Zugriff auf unternehmensinterne Reglemente zu ermöglichen. Gleichzeitig lässt sie sich für anspruchsvollere Aufgaben nutzen, wie etwa den automatisierten Abgleich externer Vorschriften – beispielsweise der FDA-Regelwerke – mit Produktbeschreibungen in der Medizinal Industrie. Dies erleichtert die Einhaltung regulatorischer Anforderungen und steigert die Effizienz im Dokumentenmanagement. Daher sind die Einsatzmöglichkeiten dieser Technologie sehr vielseitig und interessant für jede Unternehmung.
Code Repository: Bald auf GitHub verfügbar.
Bei Fragen zum Prototyp steht dir Ben gerne zur Verfügung.

Dr. Benjamin Hermberg – Chief Technology Officer
benjamin.hermberg@intersys.ch